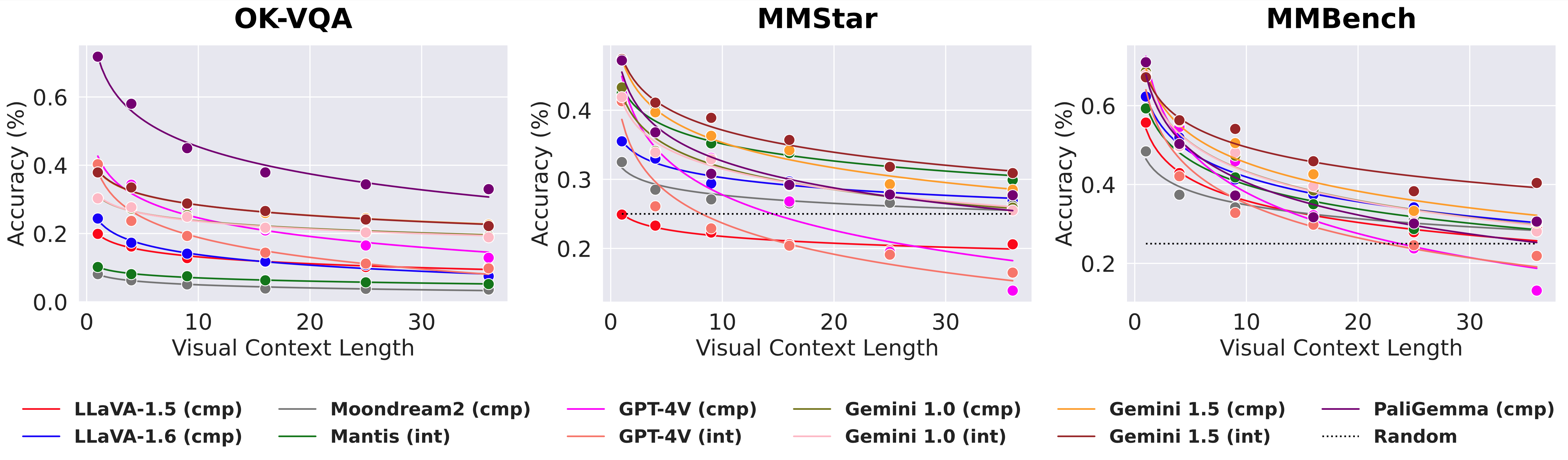
The impact of visual context on vision-language models (VLMs) in our modified, multi-image versions of the OK-VQA, MMStar, and MMBench evaluation benchmarks. Distractor images around the target image increase the visual context length needed to answer the questions. VLM performance exhibits an exponential decay against distractor count, evident in both single composed (cmp) and multiple interleaved (int) input image configurations.